واقعیت این است که فقط آدمها از سایت شما بازدید نمیکنند. تعجب نکنید! رباتهایی هم وجود دارند که در روز بارها و بارها به صفحات وبسایت شما سر میزنند و هر کدام هم وظیفهای دارند. مثلا ربات گوگل کارش این است که صفحات جدید در اینترنت را پیدا کند. این کار به ایندکس شدن این صفحات در گوگل کمک میکند و افراد میتوانند آن صفحات را ببینند.
در واقع اگر این رباتها نباشند، صفحات ارزشمند سایت شما که برای تولید آنها خیلی زحمت کشیدهاید، اصلا روی بستر اینترنت دیده نمیشوند. اما از آنجا که این رباتها ممکن است برخی چیزهایی که ما دوست نداریم را به دیگران نشان بدهند، برای کنترل کردنشان نیاز داریم تا با زبان رباتی با آنها حرف بزنیم. فایل robots.txt همان بستری است که کمک میکند تا رباتها زبان ما بفهمند.
Robots.txt یک فایل متنی است و برای رباتهای خزندهای که برای بررسی یا کارهای دیگر به وبسایت شما سر میزنند، نقش راهنما را بازی میکند.
فایل robots.txt بخشی از پروتکل REF یا robots exclusion protocol است، گروهی از استانداردهای وب که نحوه کرال کردن رباتها و همچنین دسترسی و ایندکس کردن محتوای صفحات توسط رباتها را تنظیم میکنند و این محتوا را به کاربران ارائه میدهند. لینکهای فالو و نوفالو نیز بخشی از پروتکل REP هستند.
فایل robots.txt را وبمسترها میسازند و با این فایل به رباتها دستور میدهند که چه صفحاتی را کرال یا ایندکس کنند و در چه صفحاتی نباید وارد شوند. در عمل، فایل robots.txt نشان میدهد که آیا برخی از نرمافزارهای کرال کردن وب میتوانند قسمتهایی از یک وبسایت را کرال کنند یا خیر. این دستورالعملها با «disallowing» یا «allowing» مشخص میشوند.
اصلا دستور دادن به رباتها چه فایدهای دارد؟ مگر اشکالی دارد که رباتها همینطور برای خودشان در وبسایت ما بچرند؟ بله.. اشکال دارد! اگر رباتها را کنترل نکنید، سرور هاست سایت شما درگیر رباتهایی میشود که فایدهای برای سایتتان ندارند. همچنین روی بهینهسازی سئوی سایت شما هم تاثیر میگذارد.
robots.txt چگونه کار میکند؟
موتورهای جستجو دو وظیفه اصلی دارند:
- وبسایت را برای دیسکاور کردن محتوا کرال میکنند.
- این محتوا را ایندکس میکنند تا در اختیار کاربرانی که به دنبال اطلاعات هستند قرار بگیرد.
برای کرال کردن سایتها، موتورهای جستجو لینکها را دنبال میکنند تا از یک سایت به سایت دیگر بروند. در نهایت، از طریق میلیاردها لینک وبسایت کرال میشوند. این شکل از کرال کردن، حالت عنکبوتی دارد.
پس از ورود به یک وبسایت، ربات گوگل به دنبال یک فایل robots.txt میگردد. اگر بتواند آن را پیدا کند، قبل از ادامه کرال صفحه ابتدا آن فایل را میخواند. از آنجا که فایل robots.txt حاوی اطلاعاتی درباره چگونگی خزیدن موتور جستجو است، اطلاعات موجود در این فایل، دستورالعملهای بیشتری را در اختیار ربات خزنده قرار میدهد.
اگر فایل robots.txt فاقد دستورالعملهایی باشد که فعالیت user-agent را مجاز نمیداند (یا مثلا اگر سایت، فایل robots.txt نداشته باشد)، به جستجوی سایر اطلاعات در سایت ادامه میدهد.
نکات بیشتر درباره فایل robots.txt
- یک فایل txt باید درtop-level directory وبسایت قرار بگیرد.
- txt نسبت به حروف کوچک و بزرگ حساس است: پرونده باید «robots.txt» نامگذاری شود نه به شکل Robots.txt، robots.TXT و…
- برخی از رباتها ممکن است توجهی به فایلtxt شما نکنند. این موضوع مخصوصا در رباتهای مخرب، خیلی زیاد دیده میشود.
- فایل robots.txt به صورت عمومی در دسترس است: فقط کافیست /robots.txt را به انتهای دامنه اصلی اضافه کنید تا دستورالعملهای آن وب سایت را ببینید (البته اگر آن سایت فایلtxt داشته باشد!). یعنی هر کسی میتواند ببیند شما چه صفحاتی برای کرال شدن یا نشدن مشخص کردهاید. بنابراین از آن برای مخفی کردن اطلاعات خصوصی کاربر استفاده نکنید.
چه دستوراتی در فایل robots.txt وجود دارد؟
در هر فایل robots به ۴ دستور خیلی مهم زیر احتیاج داریم:
- User-agent: در این بخش رباتی را که دستورات برای آن نوشته شده را مشخص میکنیم.
- Disallow: ربات اجازه ندارد این بخشها را بررسی کند.
- Allow: ربات میتواند این بخشها را درخواست و بررسی کند.
- Sitemap: از این دستور برای نشان دادن آدرس فایل نقشه سایت به رباتها استفاده میکنیم.
قالب اصلی دستور دادن به رباتها در robots.txt به شکل زیر است:
User-agent: [user-agent name]
Disallow: [آدرس صفحهای که نمیخواهید توسط رباتها بررسی شود]
این دو خط با هم یک فایل کامل robots.txt در نظر گرفته میشوند، هر چند یک فایل robots میتواند شامل چندین خط user agent و دستورالعمل باشد (دستوراتی مثل disallows, allows, crawl-delays و…).
اگر یک فایل robots.txt را باز کنیم، خواهیم دید که هر مجموعه از دستورالعملهای user-agent با یک «اینتر» از مجموعه دیگر جدا شده است.
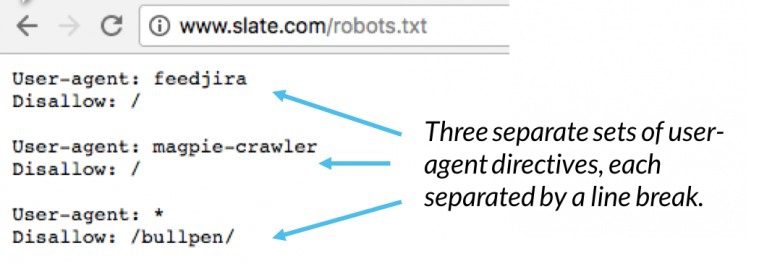
بهتر است در ادامه بررسی کنیم و ببینیم هر کدام از دستورهای فایل robots.txt دقیقا چه کاری انجام میدهند.
دستور User-agent
همانطور که قبلا توضیح دادیم، این دستور به این دلیل استفاده میشود که بتوانیم یک ربات خاص را هدف بگیریم. از این دستور به دو شکل در فایل robots.txt استفاده میکنند.
علامت ستاره یا «*» در اینجا به معنی «همه» است. اگر میخواهید به تمام رباتهای خزنده یک دستور یکسان بدهید، کافی است بعد از عبارت User-agent یک علامت ستاره بگذارید. به این شکل:
User-agent:*
اما اگر قصد دارید فقط به یک ربات خاص دستور بدهید، این دستور باید به شکل زیر نوشته شود:
User-agent: Googlebot
این دستور مشخص میکند که دستورهای موجود در فایل، تنها برای یک ربات خاص (در اینجا Googlebot) قابلیت اجرا دارد.
دستور Disallow
این دستور به رباتها میگوید که چه بخشهایی از سایت شما را نباید کرال کنند. مثلا اگر نمیخواهید موتورهای جستجو، ویدیوهای موجود در سایتتان را ایندکس کنند، همه این ویدیوها را درون یک فولدر (با نام فرضی videos) در هاستینگ خود قرار دهید و با استفاده از دستور زیر به رباتها بگویید که نباید این فولدر را بررسی کنند.
User-agent:*
Disallow: /videos
دستور Allow
ربات گول نسبت به سایر رباتها، درک بیشتری دارد و میتواند دستور Allow را هم بررسی کند. این دستور به ربات گوگل میگوید که اجازه مشاهده یک فایل، در فولدری که Disallowed شده را دارد. مثلا در کد زیر، به ربات مورد نظر میگوییم که نمیتواند فولدر videos را کرال کند:
User-agent:*
Disallow: /videos
حالا در این پوشه، ما یک فایل به اسم X.mp4 داریم که میخواهیم ربات آن را ایندکس کند. در واقع میخواهیم این فایل را مستثنی کنیم. برای این کار، دستور زیر را مینویسیم:
User-agent:*
Disallow: /videos
Allow: /videos/X.mp4
دستور Sitemap
راههای مختلفی برای دسترسی به نقشه یک سایت وجود دارد که یکی از آنها نوشتن آدرس سایتمپ در فایل robots.txt است. توجه داشته باشید این دستور فقط توسط Google ، Ask ، Bing و Yahoo پشتیبانی میشود.
robots.txt در کجای یک سایت قرار میگیرد؟
پیدا کردن فایل robots.txt کار چنداد سختی نیست. فقط کافیست آدرس اصلی سایت خود (یا هر سایت دیگری) را بنویسید و به انتهای آن یک robots.txt/ قرار دهید. به این شکل:
triboon.net/robots.txt
از اینجا میتوانید جزییات فایل robots.txt هر سایتی را به راحتی مشاهده کنید. اگر میخواهید برای ادیت فایل Robots.txt سایت خودتان اقدام کنید، این فایل در قسمت Root سایت شما قرار دارد. با ورود به این بخش میتوانید فایل robots خودتان را پیدا کنید و دستورات جدیدی به آن اضافه یا دستورات قبلی را حذف کرده و سپس فایل را ذخیره کنید.
چرا به robots.txt نیاز دارید؟
فایل Robots.txt دسترسی رباتهای خزنده به مناطق خاصی از سایت شما را کنترل میکنند. اگر به طور تصادفی اجازه ندهید Googlebot یا همان ربات گوگل به جستجوی کل سایت شما بپردازد، ممکن است به سایتتان آسیب برسد. شرایطی وجود دارد که یک فایل robots.txt میتواند برای سایت شما بسیار مفید عمل کند. برخی موارد استفاده معمول از فایل robots.txt به شرح زیر است:
- جلوگیری از نمایش محتوای تکراری در SERP. (به این نکته توجه داشته باشید که رباتهای متا معمولا گزینه بهتری برای این کار هستند)
- خصوصی نگه داشتن بخشهایی از یک وبسایت که نمیخواهید گوگل آن را ببیند یا ایندکس کند.
- جلوگیری از نمایش صفحات نتایج جستجوی داخلی در یک SERP عمومی
- تعیین محل نقشه سایت
- جلوگیری از ایندکس شدن برخی فایلهای خاص در وبسایت (تصاویر، PDF و…) توسط موتورهای جستجو
- تعیین تاخیر خزش یا crawl delay به منظور جلوگیری از بار اضافی سرورهای شما هنگام کرال شدن همزمان چندین محتوا
بهترین روشهای SEO برای فایل robots.txt
- مطمئن شوید هیچ محتوا یا بخشی از وبسایت خود را که میخواهید کرال شود، مسدود نکردهاید.
- لینکهای صفحات مسدود شده توسط txt دنبال نمیشوند؛ مگر اینکه: از سایر صفحات قابل دسترسی به موتور جستجو لینک داده شوند که در این صورت لینکهای منبع کرال نخواهند شد و ممکن است ایندکس نشوند.
- برای جلوگیری از نمایش دادههای حساس (مانند اطلاعات خصوص کاربر) در نتایج SERP از txt استفاده نکنید. با وجود دستور Disallow هنوز ممکن است گوگل صفحه شما را ایندکس کند. اگر میخواهید خیالتان برای ایندکس نشدن یک صفحه در گوگل راحت شود، از روش دیگری مانند رمز عبور محافظت شده یا دستورالعمل متنی noindex استفاده کنید.
- بعضی از موتورهای جستجو چندین user-agents دارند. مثلا گوگل از Googlebot برای جستجوی ارگانیک و از Googlebot-Image برای جستجوی تصویر استفاده میکند. اکثر رباتهای یک موتور جستجو از قوانین یکسانی پیروی میکنند، بنابراین نیازی به تعیین دستورالعملهای مختلف برای رباتهای متعدد یک موتور جستجو نیست، اما داشتن توانایی انجام این کار به شما امکان میدهد نحوه کرال شدن محتوای سایت خود را به خوبی تنظیم کنید.
- یک موتور جستجو، محتوای txt را کش میکند، اما معمولا حداقل یک بار در روز محتوای ذخیره شده را به روز خواهد کرد. اگر فایل را تغییر دهید و بخواهید سریعتر آن را به روز کنید، میتوانید آدرس robots.txt خود را در گوگل Submit کنید.